Moving average that uses less memory?
My control system gets a signal representing the plant output, but that signal has a lot of noise on it. The control system goes nuts trying to react to the noise. I need to filter out the noise somehow, but preserve the basic plant response. I heard about a moving average and tried it. It helps, but uses up a lot of memory in my small microcontroller. It also introduces some lag.
Is there a way to get rid of the noise, use less memory, and maybe have less lag too?
You can't eliminate all noise, use no memory, no processing cycles, and not add some lag. However, you can do much bet …
6mo ago
I'm adding this as a corollary to Olin's post, in case an exact formula for attenuation is needed. That basic IIR is …
4y ago
I'm adding to Olin's answer with a little bit of theory (from the standpoint of an EE) and I'm also showing a 2nd order …
5y ago
A bit of a tangent, but in mcu firmwares, higher order filters can also be implemented directly with biquad sections. Mo …
4y ago
I would suggest finding the root cause of all the noise and eliminate as much of it at the source. Baluns, active gua …
6mo ago
5 answers
You can't eliminate all noise, use no memory, no processing cycles, and not add some lag. However, you can do much better than a brute force "moving average" filter.
FIR versus IIR filters
There are two broad classes of digital filters, FIR (finite impulse response), and IIR (inifinite impulse response). There is more to it, but as a good first introduction, FIR filters are table-based, while IIR filters are equation-based.
FIR filters can realize more arbitrary filter functions, but require a lot of memory to do so. IIR filters use specific computations to get the desired filter function. This means they are limited to filter functions that can be realized by reasonable iterative equations, but generally require little state.
Basic digital low pass filter
The most common filter for reducing high frequency noise I use in situations like you describe is the IIR filter:
FILT <-- FILT + FF(NEW - FILT)
This is a single-pole low pass filter, the digital equivalent of resistor in series followed by a capacitor to ground.
FILT is a piece of persistant state. This is the only persistant variable you need to compute this filter. NEW is the new value that the filter is being updated with this iteration. FF is the filter fraction, which adjusts the "heaviness" of the filter.
Look at this algorithm and see that for FF = 0 the filter is infinitely heavy since the output never changes. For FF = 1, it's really no filter at all since the output just follows the input. Useful values are in between.
On small systems you pick FF to be 1/2N so that the multiply by FF can be accomplished as a right shift by N bits. For example, FF might be 1/16 and the multiply by FF therefore a right shift of 4 bits. Otherwise this filter needs only one subtract and one add, although the numbers usually need to be wider than the input value (more on numerical precision later).
I usually take A/D readings significantly faster than they are needed and apply two of these filters cascaded. This is the digital equivalent of two R-C filters in series, and attenuates by 12 dB/octave above the rolloff frequency. However, for A/D readings it's usually more relevant to look at the filter in the time domain by considering its step response. This tells you how fast your system will see a change when the thing you are measuring changes.
PLOTFILT program
To facilitate designing these filters (which only means picking FF and deciding how many of them to cascade), I use my program PLOTFILT. You specify the number of shift bits for each FF in the cascaded series of filters, and it computes the step response and other values. For example, here is the result of "PLOTFILT 4 4":
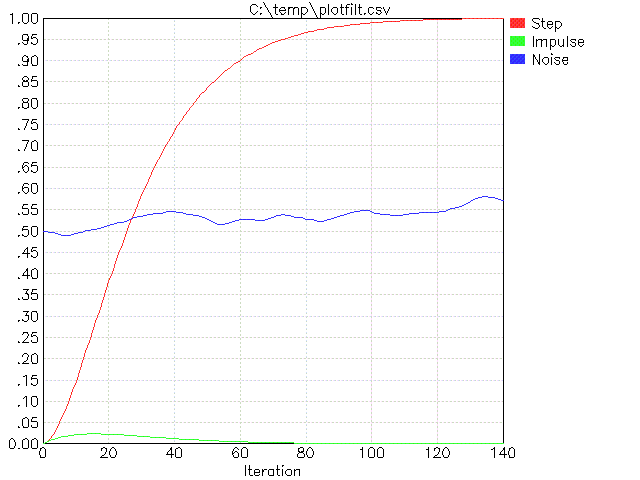
The two parameters to PLOTFILT mean there will be two filters cascaded of the type described above. The values of 4 indicate the number of shift bits to realize the multiply by FF. The two FF values are therefore 1/16 in this case.
The red trace is the unit step response, and is the main thing to look at. For example, this tells you that if the input changes instantaneously, the output of the combined filter will settle to 90% of the new value in 60 iterations. If you care about 95% settling time then you have to wait about 73 iterations, and for 50% settling time only 26 iterations.
The green trace shows you the output from a single full amplitude spike. This gives you some idea of the random noise attenuation. It looks like no single sample will cause more than a 2.5% change in the output.
The blue trace is to give a subjective feeling of what this filter does with white noise. This is not a rigorous test since there is no guarantee what exactly the content was of the random numbers picked as the white noise input for this run of PLOTFILT. It's only to give you a rough feeling of how much it will be squashed and how smooth it is.
PLOTFILT is available for free in my Full Runtime release at http://www.embedinc.com/pic/dload.htm.
Computation, noise attenutation, and delay
To some extent, the amount of computation per filter iteration, the noise attenuation, and the delay to specific settling fractions can be traded off against each other.
For example, more poles with lower shift bits each can result in the
same random noise attenuation. This example has 5 poles of 3 bits shift
each, compared to the 2 poles of 4 shift bits each above:

Note that the green trace has the same peak of about 2.5%. With the green peak held constant, more poles results in more initial delay, but a steeper eventual rise. In this case, the filter settles to values above 87% faster than the previous. This is useful if you care about 90% settling time, for example. Note, however, that 2½ times more computation is required.
Numerical precision
The multiply by FF will create Log2(FF) new bits below the binary point. On small systems, FF is usually chosen to be 1/2N so that this multiply is actually realized by a right shift of N bits. For no loss, the FILT state for each pole must be the width of the input value plus N bits.
For example, consider a 10 bit A/D reading with two poles of N = 3 (FF = 1/8) applied. For no loss, the first FILT must be at least 13 bits wide, and the second 16 bits wide.
FILT is therefore usually a fixed point integer. This doesn't change any of the math from the processor's point of view. In the example above, the first FILT could be thought of as 10.3 fixed point, and the second as 10.6 fixed point. Both can fit into what the processor considers a 16 bit integer.
To re-use the same code for each pole, it is usually convenient to have each FILT be the same format. In this case, both would be 10.6, although the low 3 bits of the first FILT would remain 0.
On most processors, you'd be doing 16 bit integer operations due to the 10 bit A/D readings anyway. In this case, you can still do exactly the same 16 bit integer opertions, but start with the A/D readings left shifted by 6 bits. The processor doesn't know the difference and doesn't need to. Doing the math on whole 16 bit integers works whether you consider them to be 10.6 fixed point or true 16 bit integers (16.0 fixed point).
Signed intermediate values
Examine the filter equation carefully, and you notice that the result of NEW - FILT can be ±NEW. This means the result of the subtract must be at least one bit wider than NEW.
For simplicity, I usually leave one extra high bit in each FILT variable. That high bit will always be 0 when the new FILT is stored, but it simplifies intermediate calculations if the same format number can be used for all values. In the example above, that would require 17 bits for the second filt, meaning 24 bits would be used on most processors. Or, you could use 11.5 fixed point for all values, and decide that the quantization noise due to the slight loss of precision in the second FILT is inconsequential in your application.
Firmware considerations
I Usually write a subroutine or macro to perform one filter pole operation, then apply that to each pole. Whether a subroutine or macro depends on whether cycles or program memory are more important in that particular project. The amount of program memory available in microcontrollers has grown such that it hasn't been a limitation in recent projects, so I mostly use a macro now.
I use some scratch state to pass NEW into the subroutine/macro, which updates FILT, but also loads that into the same scratch state NEW was in. This makes it easy to apply to multiple poles since the updated FILT of one pole is the NEW of the next pole. It can be useful to have a pointer point to FILT on the way in, which is updated to just after FILT on the way out. That way the filter routine automatically operates on consecutive filters in memory if called multiple times.
Here is one such filter macro. This is in assembler on a Microchip dsPIC, using my PREPIC preprocessor (also available for free in the Full Runtime release mentioned above):
////////////////////////////////////////////////////////////////////////////////
//
// Macro FILTER ffbits
//
// Update the state of one low pass filter. The new input value is in W1:W0
// and the filter state to be updated is pointed to by W2.
//
// The updated filter value will also be returned in W1:W0 and W2 will point
// to the first memory past the filter state. This macro can therefore be
// invoked in succession to update a series of cascaded low pass filters.
//
// The filter formula is:
//
// FILT <-- FILT + FF(NEW - FILT)
//
// where the multiply by FF is performed by a arithmetic right shift of
// FFBITS.
//
// WARNING: W3 is trashed.
//
/macro filter
/var local ffbits integer = [arg 1] ;get number of bits to shift
/write
/write " ; Perform one pole low pass filtering, shift bits = " ffbits
/write " ;"
sub w0, [w2++], w0 ;NEW - FILT --> W1:W0
subb w1, [w2--], w1
lsr w0, #[v ffbits], w0 ;shift the result in W1:W0 right
sl w1, #[- 16 ffbits], w3
ior w0, w3, w0
asr w1, #[v ffbits], w1
add w0, [w2++], w0 ;add FILT to make final result in W1:W0
addc w1, [w2--], w1
mov w0, [w2++] ;write result to the filter state, advance pointer
mov w1, [w2++]
/write
/endmac
I'm adding this as a corollary to Olin's post, in case an exact formula for attenuation is needed.
That basic IIR is derived from the exponential moving average, and its impulse response is:
$$h[n]=\alpha x[n]+(1-\alpha)x[n-1]$$
which translates into this transfer function:
$$H(z)=\frac{\alpha}{1-(1-\alpha)z^{-1}}$$
This can be used to determine analytically the attenuation at a particular frequency, by simply substituting $z^{-1}=\text{e}^{-j\Omega}$:
\begin{align*} H(j\Omega)=\frac{\alpha}{1-(1-\alpha)\text{e}^{-j\Omega}} \\ |H(j\Omega)|=\frac{\alpha}{\sqrt{2(\alpha-1)(\cos(\Omega)-1)+\alpha^2)}}\tag{1} \end{align*}
The -3 dB point can also be calculated from $(1)$:
\begin{align*}|H(\Omega)|^2=\frac12=\frac{\alpha^2}{2(\alpha-1)(\cos(\Omega)-1)+\alpha^2}\quad\Rightarrow \\ 2(\alpha-1)(\cos(\Omega)-1)+\alpha^2=2\alpha^2\quad\Rightarrow \\ \cos(\Omega)-1=\frac{\alpha^2}{2(\alpha-1)}\quad\Rightarrow \\ \Omega=\arccos\left(1+\frac{\alpha^2}{2(\alpha-1)}\right)\end{align*}
This can be easily tested with any simulator. As an example, for $\alpha=0.4$, the attenuation at $0.37\frac{f_s}{2}$ and the -3 dB point are:
\begin{align*} |H(0.37\pi)|=\frac{0.4}{\sqrt(2(0.4-1)(\cos(0.37\pi)-1)+0.4^2)}=0.4255746548210215 \\ f=\frac{1}{\pi}\arccos\left(\frac{0.4^2}{2(0.4-1)}+1\right)=0.1662579714811903 \end{align*}
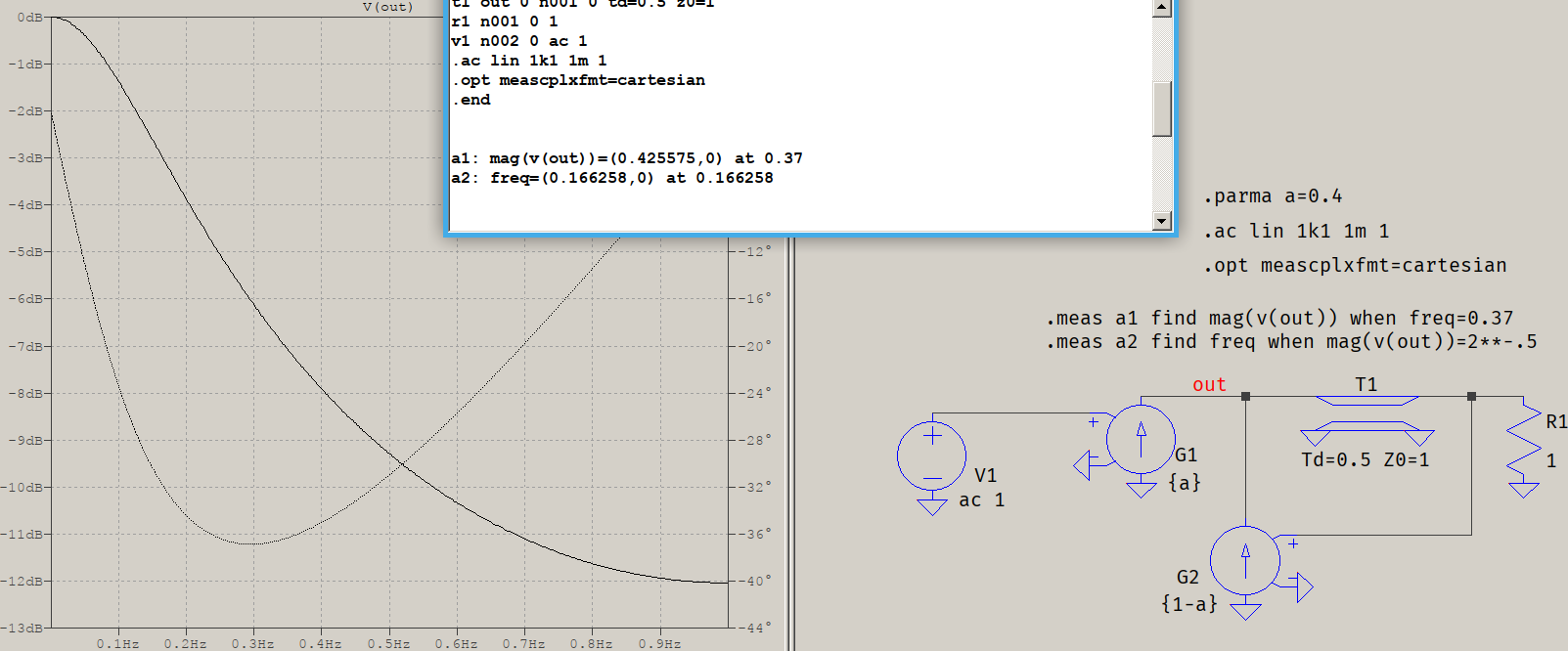
(where I used a normalized [0...Nyquist])
I'm adding to Olin's answer with a little bit of theory (from the standpoint of an EE) and I'm also showing a 2nd order IIR filter. The 2nd order filter is based on cascading two 1st order stages with an additional feedback loop to control Q factor (or $\zeta$).
Both these filters are IIR types of the type discussed by Olin: -
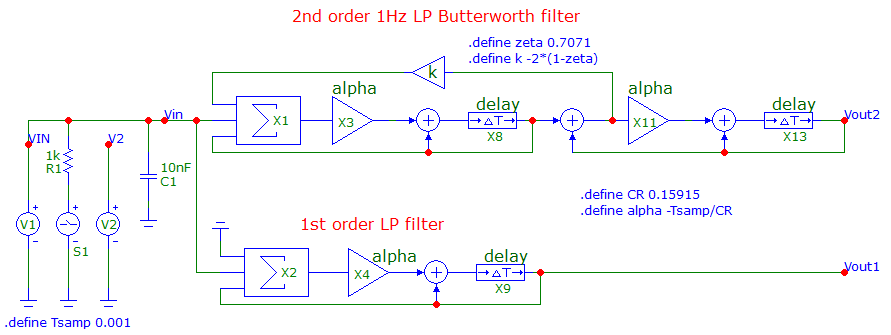
There are two filters in the above diagram: -
- 1st order 1 Hz low pass filter
- 2nd order 1 Hz low pass filter
The 2nd order low pass filter has been adjusted to give a Butterworth response i.e. maximally flat in the pass band. The sample rate is 1 kHz.
The AC responses are: -
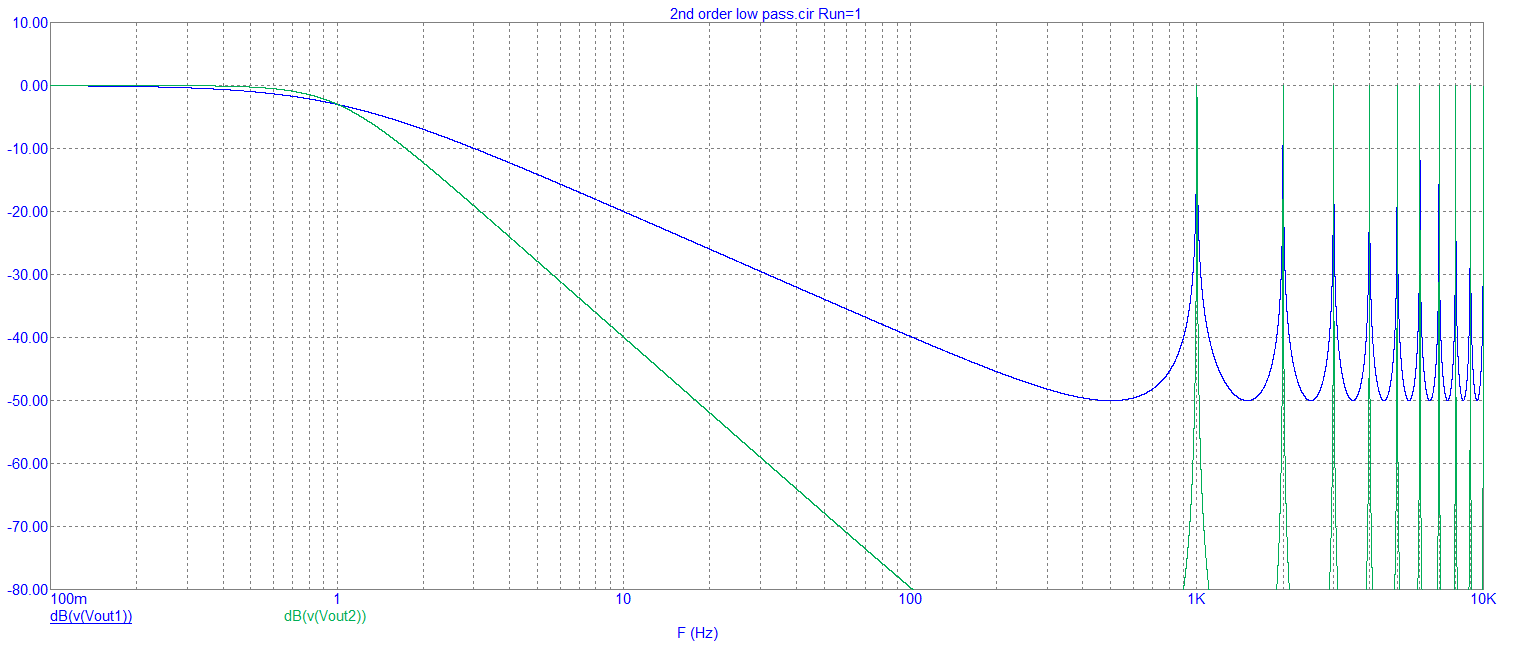
And the 10 Hz signal input transient responses are: -
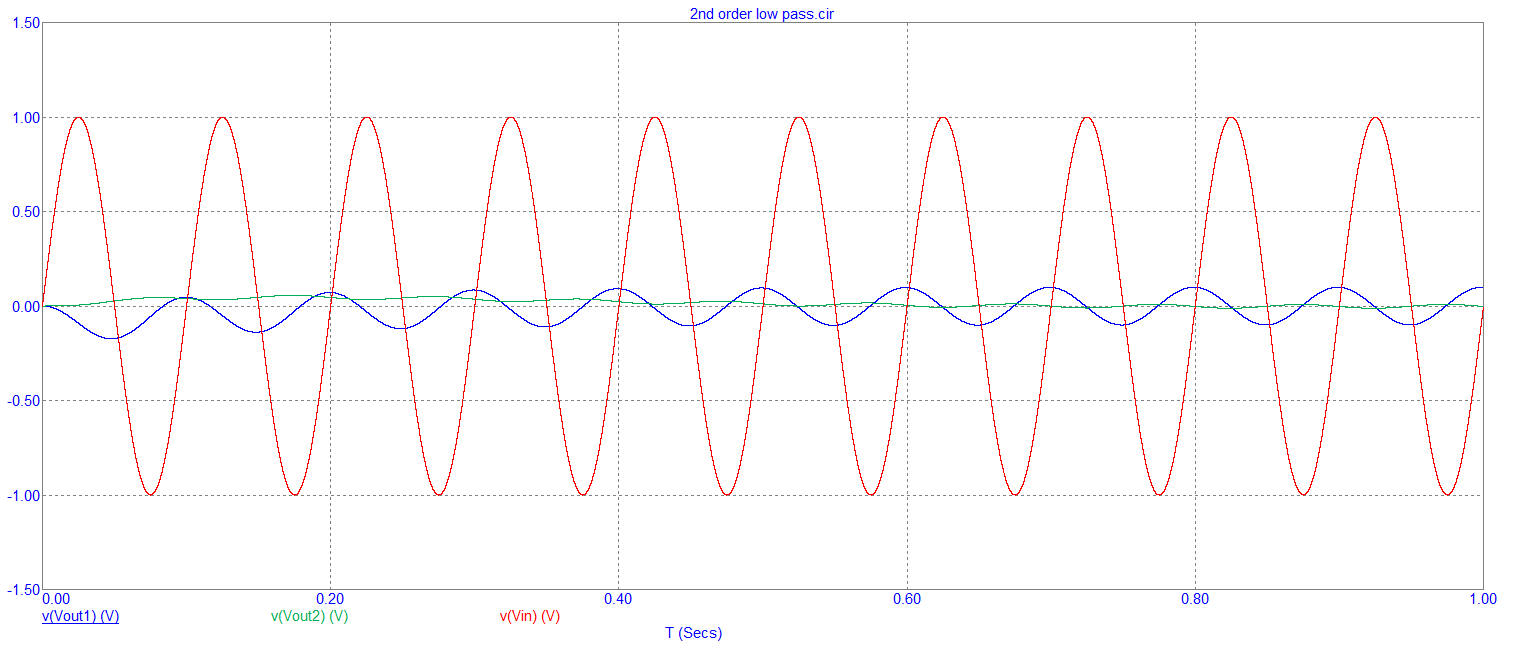
Several things are defined in the "schematic": -
- Tsamp is the sample time (set to 1 ms)
- CR is the capacitor-resistor time constant (set to 0.15915)
- This CR time is for a 1 Hz low pass filter because: -
$$F_C = \dfrac{1}{2\pi CR} = 1 \text{ Hz}$$
Those definitions suit both filters and, for the 2nd order filter, there is a definition that sets the damping: -
- zeta (damping ratio or $\zeta$) is set to 0.7071 (classical Butterworth response)
- k is the feedback factor and equals $-2\cdot(1 - \zeta)$
On the left of the schematic is: -
- V1, an analogue voltage source to provide an input
- V2, a square wave source for sampling V1
- S1, does the sampling for transient analysis
This answer is aimed at the occasional coder who knows about analogue circuits and wondered how a simple CR circuit can be transformed into the z-plane.
Here's the equivalent analogue circuit: -
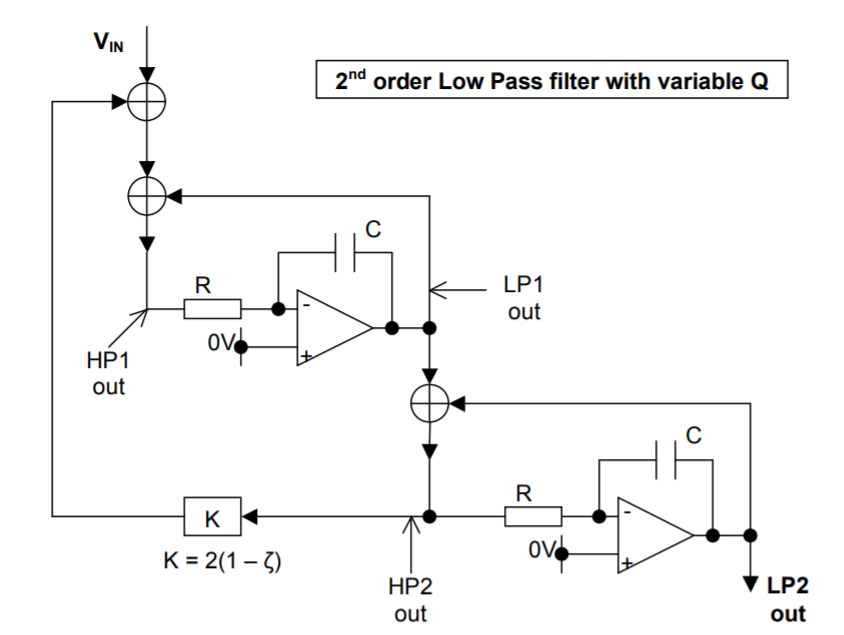
Maybe of interest is that the HP2 node is also a band-pass output.
If we change zeta and concentrate on the 2nd order output we get: -
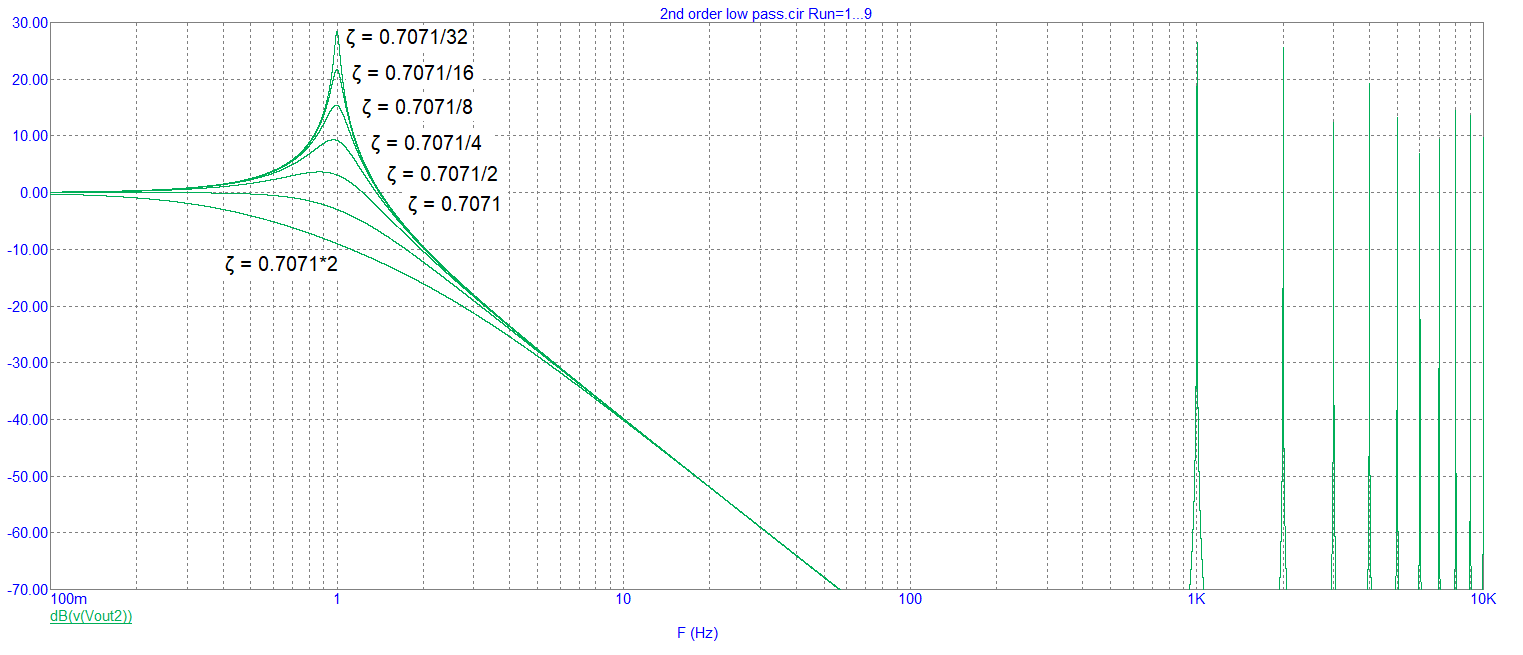
Which is "as expected" for this type of filter.
0 comment threads
A bit of a tangent, but in mcu firmwares, higher order filters can also be implemented directly with biquad sections. More work to implement vs single pole, but very reusable. Although to be honest the benefit over cascaded single-poles is marginal, so there may be other topics, like loop stability, that might be a better use of someone's time, if they are at the stage when asking the question originally posted.
The main difference betw. biquads and single-pole's is the ability to place complex poles and zeros. IMO this is not actually desirable for filtering process data from typical sensors, due to underdamped step response.
On the other hand ability to place complex poles and zeros CAN open up more options when put to use inside a control loop, for more difficult situations. You have to kindof enjoy the math to take this route.
0 comment threads
I would suggest finding the root cause of all the noise and eliminate as much of it at the source.
Baluns, active guarding, double shielding, buffering, current source control and matched impedance T-lines are some of the methods to do that.
Define your existing SNR and desired result. Then recheck the step response on your loop for opportunities for improvements.
Looks like you got great filter advice already.
It would help if you showed the noise spectrum.
0 comment threads

0 comment threads